RAG is a technique that combines a large language models (LLM) with an information retrieval (IR) component, enabling the LLM to access and utilize external knowledge sources to enhance its responses. By anchoring its responses to real-world facts and information, RAG can address the limitations of LLMs in knowledge-intensive tasks.
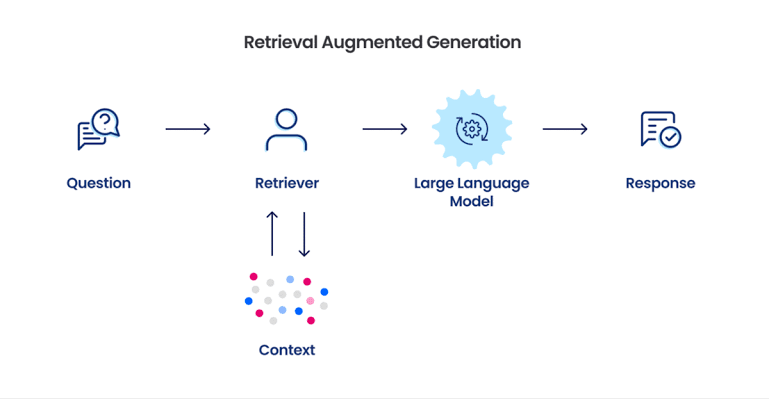
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), demonstrating remarkable capabilities in tasks such as text generation, translation, and question answering. However, despite their impressive progress, LLMs often struggle with tasks that require access to factual knowledge beyond their internal representation of language. This is where retrieval-augmented generation (RAG) comes into play.
RAG is a technique that combines an LLM with an information retrieval (IR) component, enabling the LLM to access and utilize external knowledge sources to enhance its responses. By anchoring its responses to real-world facts and information, RAG can address the limitations of LLMs in knowledge-intensive tasks.
The Challenges of Knowledge-Intensive Tasks for LLMs
LLMs are trained on massive amounts of text data, which allows them to capture statistical relationships between words and phrases. This enables them to generate human-quality text, translate languages, and answer questions in an informative way. However, their ability to access and manipulate factual knowledge is limited, making them less effective in tasks that require a deep understanding of the world.
For instance, an LLM might struggle to answer a question about the latest scientific discovery or provide accurate information about a historical event. This is because their internal representation of language may not contain the specific facts or concepts required to answer such questions.
The Benefits of RAG
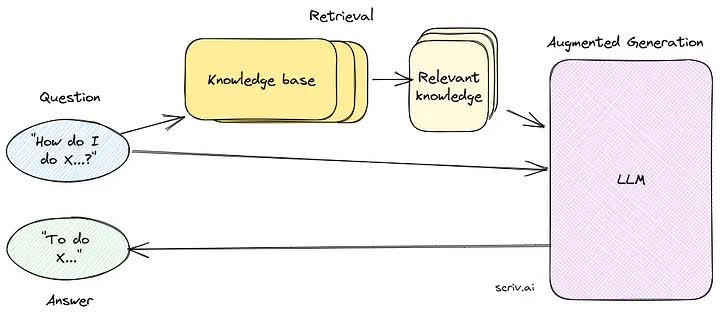
RAG addresses these limitations by providing LLMs with access to external knowledge sources, such as Wikipedia, scientific journals, or other relevant databases. The IR component identifies relevant documents or passages that contain the information needed to answer the query. These retrieved documents are then concatenated with the original input prompt and fed to the LLM, which generates its response based on the combined input.
Retrieval-Augmented Generation (RAG): Enhancing Large Language Models with External Knowledge
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), demonstrating remarkable capabilities in tasks such as text generation, translation, and question answering. However, despite their impressive progress, LLMs often struggle with tasks that require access to factual knowledge beyond their internal representation of language. This is where retrieval-augmented generation (RAG) comes into play.
RAG is a technique that combines an LLM with an information retrieval (IR) component, enabling the LLM to access and utilize external knowledge sources to enhance its responses. By anchoring its responses to real-world facts and information, RAG can address the limitations of LLMs in knowledge-intensive tasks.
The Challenges of Knowledge-Intensive Tasks for LLMs
LLMs are trained on massive amounts of text data, which allows them to capture statistical relationships between words and phrases. This enables them to generate human-quality text, translate languages, and answer questions in an informative way. However, their ability to access and manipulate factual knowledge is limited, making them less effective in tasks that require a deep understanding of the world.
For instance, an LLM might struggle to answer a question about the latest scientific discovery or provide accurate information about a historical event. This is because their internal representation of language may not contain the specific facts or concepts required to answer such questions.
The Benefits of RAG
RAG addresses these limitations by providing LLMs with access to external knowledge sources, such as Wikipedia, scientific journals, or other relevant databases. The IR component identifies relevant documents or passages that contain the information needed to answer the query. These retrieved documents are then concatenated with the original input prompt and fed to the LLM, which generates its response based on the combined input.
This approach offers several benefits:
Improved factuality: By grounding its responses on external knowledge, RAG ensures that the generated text is consistent with real-world facts.
Enhanced specificity: RAG can provide more specific and detailed answers to questions, as it has access to a wider range of information than is contained in its internal representation of language.
Adaptability to evolving knowledge: RAG is more adaptable to changes in knowledge, as it can
easily incorporate new information from external sources without requiring the LLM to be retrained.
Retrieval-Augmented Generation (RAG): Enhancing Large Language Models with External Knowledge
Large language models (LLMs) have revolutionized the field of natural language processing (NLP), demonstrating remarkable capabilities in tasks such as text generation, translation, and question answering. However, despite their impressive progress, LLMs often struggle with tasks that require access to factual knowledge beyond their internal representation of language. This is where retrieval-augmented generation (RAG) comes into play.
RAG is a technique that combines an LLM with an information retrieval (IR) component, enabling the LLM to access and utilize external knowledge sources to enhance its responses. By anchoring its responses to real-world facts and information, RAG can address the limitations of LLMs in knowledge-intensive tasks.
The Challenges of Knowledge-Intensive Tasks for LLMs
LLMs are trained on massive amounts of text data, which allows them to capture statistical relationships between words and phrases. This enables them to generate human-quality text, translate languages, and answer questions in an informative way. However, their ability to access and manipulate factual knowledge is limited, making them less effective in tasks that require a deep understanding of the world.
For instance, an LLM might struggle to answer a question about the latest scientific discovery or provide accurate information about a historical event. This is because their internal representation of language may not contain the specific facts or concepts required to answer such questions.
The Benefits of RAG
RAG addresses these limitations by providing LLMs with access to external knowledge sources, such as Wikipedia, scientific journals, or other relevant databases. The IR component identifies relevant documents or passages that contain the information needed to answer the query. These retrieved documents are then concatenated with the original input prompt and fed to the LLM, which generates its response based on the combined input.
This approach offers several benefits:
Improved factuality: By grounding its responses on external knowledge, RAG ensures that the generated text is consistent with real-world facts.
Enhanced specificity: RAG can provide more specific and detailed answers to questions, as it has access to a wider range of information than is contained in its internal representation of language.
Adaptability to evolving knowledge: RAG is more adaptable to changes in knowledge, as it can easily incorporate new information from external sources without requiring the LLM to be retrained.
Applications of RAG
RAG has been successfully applied to a variety of NLP tasks, including:
Question answering: RAG can provide more accurate and comprehensive answers to open-ended, challenging, or strange questions.
Fact verification: RAG can assess the factual accuracy of statements or claims by checking them against external sources.
Summarization: RAG can generate summaries of complex or lengthy documents, ensuring that key facts and information are retained.
Creative writing: RAG can incorporate external knowledge into creative writing tasks, such as generating stories or poems that are consistent with historical or scientific facts.
Here are some specific examples of RAG usage and statistics:
A recent study by Microsoft Research found that RAG can improve the accuracy of question answering systems by up to 20%.
A study by Google Research found that RAG can improve the quality of machine translation output by up to 10%.
A study by OpenAI found that RAG can be used to generate more creative and interesting text formats, such as poems, code, scripts, musical pieces, email, letters, etc.
A recent survey by Analytics Vidhya found that over 70% of respondents are aware of RAG, and that over 50% of respondents are interested in using RAG in their own projects. This suggests that RAG is gaining recognition and traction within the NLP community.
Conclusion
Retrieval-augmented generation (RAG) is a promising technique that enhances the capabilities of large language models by providing them with access to external knowledge sources. By grounding its responses on real-world facts, RAG can improve the accuracy, specificity, and adaptability of LLM-generated text. As RAG continues to develop, it is likely to play an increasingly important role in a variety of NLP applications.